论文 Scalable Edge Blocking Algorithms for Defending Active Directory Style Attack Graphs
阅读笔记,2023 AAAI。
摘要
AD(活动目录, Active Directory)可以看做是一个攻击图,其中节点代表计算机/账户/安全组,边代表现有访问权限/已知漏洞,这些访问权限/漏洞允许攻击方从一个节点访问另一个节点。
与许多仅具有理论性质的攻击图模型不同,AD 攻击图正在被实际攻击者和 IT 管理员积极使用。已开发了多个软件工具(包括开源和商业软件),用于扫描、可视化和分析 AD 图。
比如 BLOODHOUND,模拟了身份雪球攻击。攻击者从一个低权限帐户开始,这被称为攻击者的入口节点(例如,通过钓鱼邮件获得)。然后,攻击者从一个节点移动到另一个节点,最终目标是获取名为 DA(域管理员,Domain Admin)的最高权限帐户。
研究目的
如何通过付出最小的代价来阻断攻击线路,降低攻击者获取 DA 权限的成功率。
如果一个 IT 管理员需要 1 小时来阻断 1 条线路(包括审计、报告、实施),并且一天有 8 小时工作时间,那么代价 b = 8。
且一些线路是企业正常运营所必须的,阻断的代价相当昂贵。
在本文的模型中,假设不同的线路具有不同的攻击失败率,而阻断攻击线路即是将攻击失败率提升至 100%。
本文的重点不在于推进固定参数分析(fixed-parameter analysis)的理论前沿,这只是在 AD 图上设计可扩展算法的手段。
实际上,本文的研究方法结合了固定参数分析和实际优化技术(practical optimisation techniques)。
AD 图的结构特征
观察到实际 AD 图有两个明显的结构特征。
攻击路径倾向于很短
这是一种尚未经证实的观察,但本文认为在实际应用中这是合理的。
并不是说长路径不存在,指攻击方实际使用的最短路径。
BLOODHOUND 团队类比了著名的“六度分隔”理念,即,这个世界上的所有人平均通过六步或更少的社交连接就能相互联系。在域中也一样,在一个组织中,从一个实习生的账户到 CEO 的账户通常只需要几步。
AD 图与树非常相似
人力资源部门可能构成一个树枝,而市场营销部门则形成另一个树枝。
但不完全对,因为人力资源部门的一个账户可能有合理的理由访问属于市场营销部门的计算机上的数据。
可以将活动目录攻击图解释为带有额外非树边的树,这些非树边代表安全例外。
工作内容
- 为纯策略和混合策略的最优边缘阻塞设计实际可扩展的算法。
对于内网中拥有数千台计算机的组织,AD 图通常涉及数万个节点。本文通过利用 AD 图的结构特征,成功地扩展到这样的规模。
- 证明仅有短攻击路径不足以推导出高效的阻断策略。
即使最大攻击路径长度是一个常数,纯策略和混合策略阻断都是 NP 难的。
- 探索 AD 图的树状特征。
策略设计
纯策略(pure strategy)
毫不犹豫地阻断 \(b\) 个线路。
采用 Stackelberg 博弈模型,假设攻击者可以观察到防御者的策略并采取最佳反应。
Stackelberg 博弈模型,在这个模型中,通常有两家公司:一家是“领导者”,另一家是“追随者”。领导者公司首先采取行动,然后追随者公司在观察了领导者的决定后作出决策。
可以简化为单源单目的地最短路径边界阻断问题。
这被认为是 NP 难的,但是在一般图上的 NP 难并不意味着 AD 图上无法找到高效算法。
参数计算方法通常将一个优化问题(以最小值问题为例)转化为参数化问题“判定问题是否存在一个大小至多为参数 k 的解”。
一个参数化问题如果可以在时间 \(O(f(k)n^{O(1)})\) 内求解,其中 \(f(k)\) 是一个关于参数 k 的单调非减函数,n 为实例的规模,则该问题称为固定参数可解的 (Fixed-Parameter Tractable),习惯上用 FPT 表示该类问题的集合,相应的算法称为固定参数可解算法。
混合策略(mixed strategy)
注明了多组 \(b\) 个线路组合和选择对应组合的概率。
攻击者只能观察到选择阻断组合的概率,而不能观察到实际的选择情况。
方法设计
方法一
针对纯策略的阻塞。
对于数宽较小的,本文使用了一个基于树分解的动态规划方法,然后将其转化为强化学习环境。
树分解 Tree decomposition
图的树分解是为了简单无向图尽可能地分解为树形结构,通过研究树上的结构信息来刻画原图的一些性质。
在实际应用中,很多问题涉及的图的规模都很大,直接求解的难度也很高。若将这类问题的图转化为树,则可在多项式时间甚至线性时间内求解问题。
图的树分解是对图 \(G\) 的结点集进行划分,生成与之对应的一棵分解树 \(T\),\(T\) 中的节点 \(i\) 对应 \(G\) 的一个结点子集 \(X_i\)。
对于简单无向图 \(G=(V,E)\),其树分解是 \(T_G=(X,T)\),其中 \(T=(I,F)\) 是一颗有根树,\(I\) 为其点集,也称作包,\(F\) 为其边集。
\(X=\{X_i:i \in I\}\) 是一个 \(V\) 的子集族。其满足以下条件:
- \(\underset{i \in I}{\cup}X_i=V\),即所有的子集族并集等于 \(G\) 的结点集。
- 对于 \(\forall (u,v) \in E,\exists \, i \in I\), 存在 \(u,v \in X_i\),即 \(G\) 中每条边的两个节点必存在于某个子集中。
- 对于 \(i,j,k \in I\), 如果 \(T\) 中 \(k\) 出现在 \(i\) 到 \(j\) 到一条路径上,则有 \(X_i \cap X_j=X_k\)。
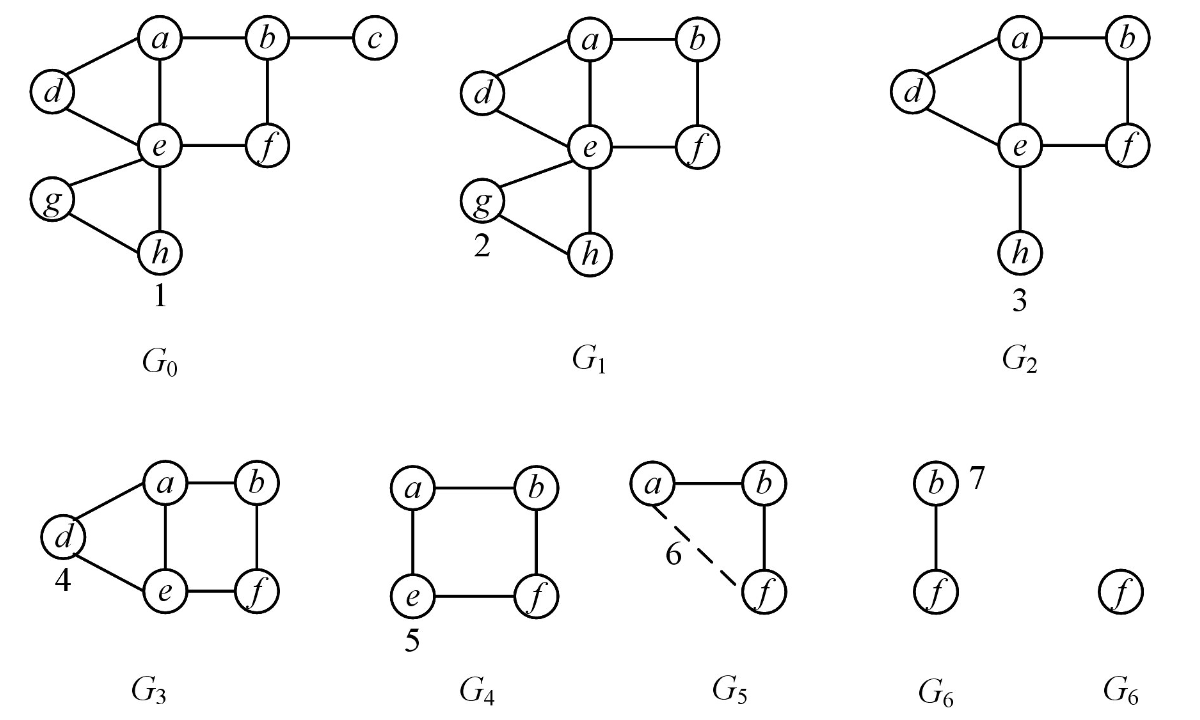
示例
消序
上图使用最小度、最小填边数优先排序的贪心算法产生一个消点序。
遍历最小度,生成一个结点集 \(MV_i\)。
遍历 \(MV_i\),选择一个节点 \(v\),要求其邻域 \(N(v)\) 中任意两点未相连的边数量最少。
然后删除节点 \(v\) 和与其相邻的边,并将 \(N(v)\) 中未相连的边集 \(F_i\) 也加入。
最后根据删除的节点 \(v\),生成一个消点序 \(V=\{\pi^{-1}(1),...,\pi^{-1}(n)\}\)【\(\pi\) 为点和次序的双射排列】。 \[ \pi=\begin{pmatrix} a & b & c & d & e & f & g & h \\ 6 & 7 & 1 & 4 & 5 & 8 & 2 & 3 \end{pmatrix} \]
合并 \(F\) 到 \(E\),就可以得到图 \(G\) 的三角剖分。【大概是多了 \(G_5\) 的那条虚线边吧,大概】
生成包序列
\[X_1=N_G[v_1]=N_G(v_1) \cup \{v_1\}\] \[X_2=N_{G_{[e(v_1)]}}(v_2) \cup \{v_2\}\] \[...\] \[X_k=N_{G_{[e(v_1,...,v_{k-1})]}}(v_k) \cup \{v_k\}\] \[...\] \[X_n=\{v_n\}\]
\(G_{[e(v_1,...,v_{k-1})]}\) 表示依次从 \(G\) 中删去 \(V_i\) 产生的图,然后得到下面这玩意。 \(X_8=\{f\},X_7=\{b,f\},X_6=\{a,b,f\},X_5=\{e,a,f\},X_4=\{d,a,e\},X_3=\{h,e\},X_2=\{g,e,h\},X_1=\{c,b\}\)。
合并部分节点包
\[X_8 \subset X_7 \subset X_6 = \{a,b,f\}, 8 = max\{6,7,8\}\] \[X_3 \subset X_2 = \{g,e,h\}, 3 = max\{2,3\}\] \[X_5 = \{e,a,f\}, X_4 = \{d,a,e\}, X_1 = \{c,b\}\] \[I=\{1,3,4,5,8\}\]
最后得到分解树
树宽度
引入树宽的概念是为了反映给定的图形结构与分解后的树形结构的相似程度。
较小的树宽表示该图接近于一棵树。
图本身是树时,树宽为 \(1\)。
宽度为所有片段 \(X\) 的大小的最大值减 \(1\),\(max(|X_i|-1)\)。
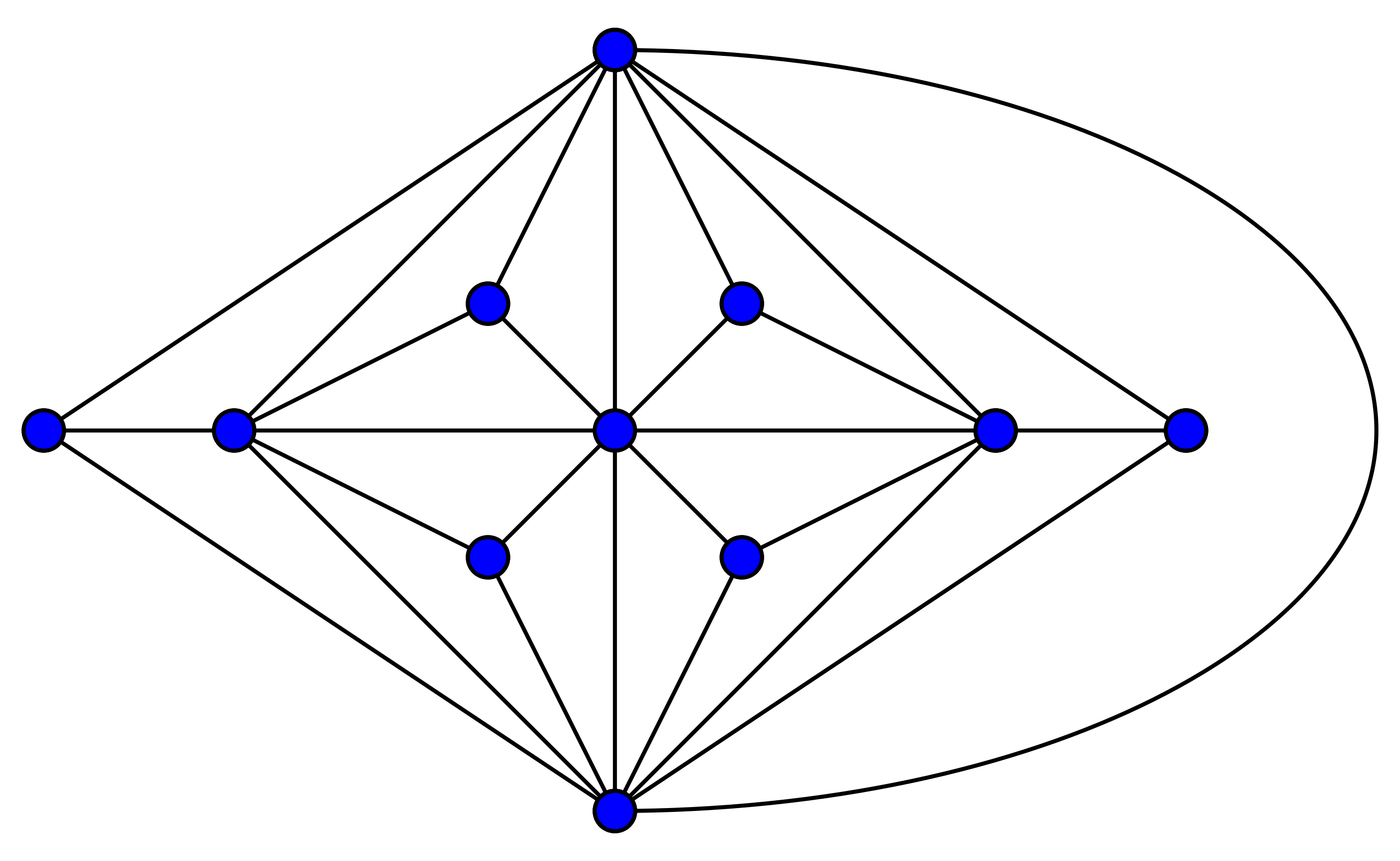
K-Tree
K-Tree 是往一个 K+1 顶点的完全图里加顶点,使得每个新加的顶点 v 都有 K 个邻居 U,这样,v 和 U 合起来共计 K+1 个顶点构成一个 Clique。
如下图,K=3,即初始为 4 顶点完全图。
Treewidth 为 K 的图是 K-Tree 的子图,因此被称为 A partial K-Tree。
这使得 Anytime Algorithm 具有更好的拓展性,但是无法保证最优。
任意时间算法(Anytime Algorithm)更多的是一种算法设计的概念或思想,而不是一个具体的、固定的算法框架。这种算法的核心特点是能够在任何时候停止执行,并提供当前已得到的最佳解决方案。这对于时间敏感或计算资源受限的应用场景特别重要。
方法二
处理纯策略和混合策略的阻塞。
为了应对 AD 图上的特定应用,提出了一种非标准的固定参数。
常规的攻击路径描述了一条权限提升路径。
一个节点拥有多个权限提升出边是罕见的【因为这样的边通常代表安全例外或配置错误】。
本文观察到实际的AD图包含非分割路径【本文提出的特征:每个节点都有一条出边的路径】,对于非分裂路径数量较少的图,本文提出了核化技术来缩小模型规模,然后通过混合整数规划求解。
混合整数规划求解
Food Cost per serving Vitamin A Calories Corn 0.18 107 72 2% Milk 0.23 500 121 Wheat Bread 0.05 0 65 超市里头有卖 3 种食品,玉米,牛奶和面包,价格,所含的维他命 A 和卡路里的信息见上表。现在的问题是买多少份的玉米,牛奶,面包,使得总价格最低,而维他命 A 的总摄取量不小于 500 但不大于 50000,卡路里的总摄取量不小于 2000 但不大于 2250。这个问题的数学描述如下:
\[min: 0.18X_{corn}+0.23X_{milk}+0.05X_{bread}\]
\[s.t.,\]
\[107X_{corn}+500X_{milk}\le50000\]
\[107X_{corn}+500X_{milk}\ge500\]
\[72X_{corn}+121X_{milk}+65X_{bread}\le2250\]
\[72X_{corn}+121X_{milk}+65X_{bread}\ge2000\]
\[X_{corn},X_{milk},X_{bread}\ge0\]
现在回到之前的问题,如果在线性规划问题中有部分决策变量,比如上面的 \(X_{corn}\) 要求必须是整数, 那么这时的规划问题就转变成混合整数线性规划问题了。
这样,本文提出的算法可以扩展处理包含数万个节点的合成 AD 图。
模型描述
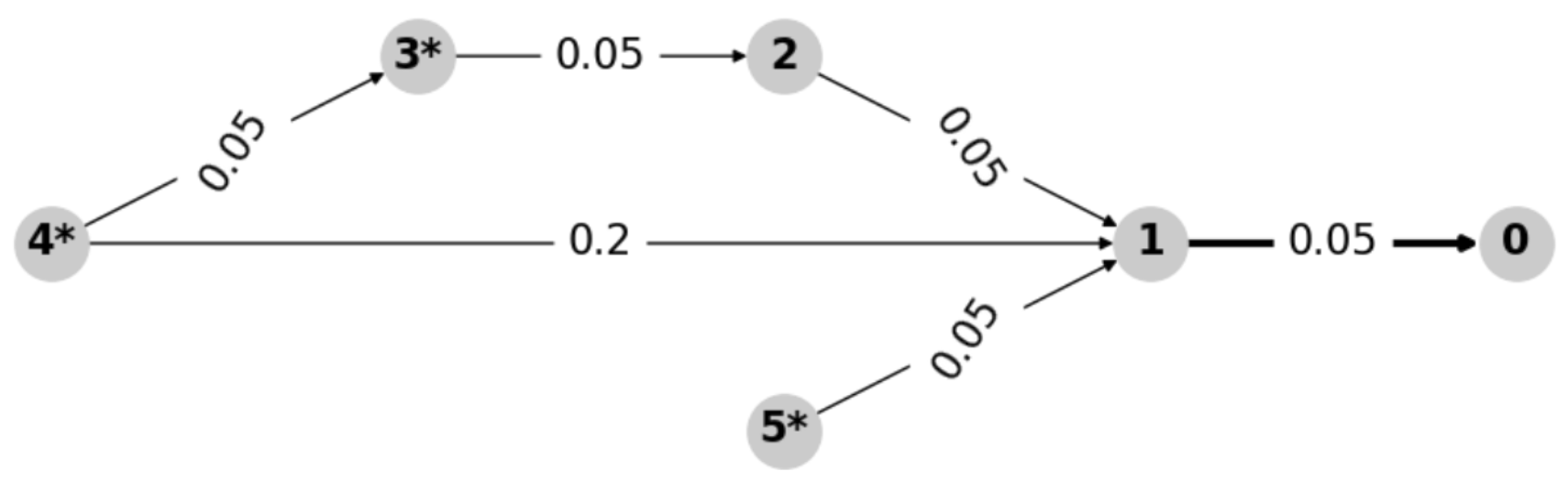
如图所示,本文使用有向图 \(G=(V,E)\) 来描述 AD 环境,每条边 e 都有一个攻击的失败率 \(f(e)\)。
节点 0 是 DA。节点 3、4、5 是入口节点(用 * 标记),边标签代表边的失败率,粗边(即 1 → 0)不可阻断。
有一个目的节点 DA 和 s 个入口节点。攻击方可以从任意入口节点出发,选择任意路径。
目标是通过选择最佳入口节点和最佳攻击路径,最大限度地提高到达 DA 的成功率。
防守方从一组可阻断的边 \(E_b \subseteq E\) 中选择 b 条边进行阻断,其中 b 是防御预算。
防守方的目标是最小化攻击方攻击成功的概率。
约束预算 \(\sum_{e \in E_b} B(e) \leq b\)。
- 纯策略阻塞: \(B(e)\) 等于 \(0\) 或 \(1\)。
- 混合策略阻塞: \(B(e)\) 在 \([0, 1]\) 之间。
给定 B,可以通过以下公式找到攻击者的最优攻击路径:\(max_{p\in P}\{\prod_{e\in p}(1-f(e))(1-B(e))\}\),其中 P 是所有入口节点到所有攻击路径的集合。
这个最大化问题等价于 \(min_{p\in P}\{\sum_{e\in p}(-ln(1-f(e))-ln(1-B(e)))\}\)。
通过应用自然对数将乘积转换为求和,本文将一条边的“距离”视为 \(-ln(1-f(e))-ln(1-B(e))\) 【非负数】。
攻击者的最优攻击路径可以使用 Dijkstra 的最短路径算法。
\(SR(B)\) 表示面对阻挡策略 \(B\) 的攻击者的成功率,防御者的问题是最小化 \(SR(B)\),即降低攻击者的成功率。
本文的第一个结果是一个负面结果,表明仅有短攻击路径是不足以推导出高效算法的。也就是说,接下来确实需要考虑树状特征。
说实话读到这里的时候我没找到文中所谓的负面结果究竟指什么。
定理1:对于常数最大攻击路径长度,纯策略和混合策略阻挡都是NP难的。
由于篇幅限制,证明被推迟到附录中。
用于纯策略阻挡的基于动态规划的树分解
对于普通图的许多NP难的组合问题,如果专注于树宽度小的图,这些问题就变得易于处理。
本文使用节点来指代树分解中的树节点,使用顶点来指代 AD 图中的顶点。
两个假设
- 树宽较小
- 一条路径的成功率来自一个最多包含 H 个值的小集合
路径的成功率是攻击者在没有任何阻挡的情况下通过它的成功率,如果所有边都有相同的失败率,则 H 仅为最大攻击路径长度 l+2(0~l 跳,加上“无路径”)。
- 0 到 l 跳:这表示攻击路径可以从 0 跳(即没有任何移动,路径长度为 0)到 l 跳(路径包含 l 个移动步骤)。这里的 l 代表攻击路径的最大长度。
- “无路径”:这是一个特殊情况,指的是不存在从起点到终点的有效路径。在分析攻击路径时,考虑“无路径”的情况是重要的,因为它表示攻击者无法成功到达目标。
一般来说,如果边的类型数量是一个小常数 k,那么 \(H \in O(l^k)\)。
在本文的实验中,假设有两种类型的边【高失败率和低失败率】,因此有 \(H \in O(l^2)\),【H 仅用于最坏情况下的复杂性分析】。
在实验中,对于给定的特定图,一条路径可能的成功率数量通常显著较少。
步骤
本文的动态规划称为 TDCYCLE(具有循环的树分解),其将攻击图视为一个无向图,然后生成一个树分解。
在本文的实验中,采用顶点消除启发式方法生成树分解。
然后将得到的树分解转换为 nice 树分解,其中根节点是一个只包含 DA 的包,所有叶节点是大小为 1 的包。
本文用 \(TD\) 来表示得到的 nice 树分解。\(TD\) 有 \(O(wn)\) 个节点,其中 \(w\) 是树宽度。
引理 1
设 \((u, v)\) 是 AD 图中的任意一条边。在 \(TD\) 下,有且仅有一个“遗忘”节点 \(X\),其子节点记为 \(X'\),其中 \(\{u, v\} \subseteq X'\) 且 \(X' \backslash X\) 是 \(\{u\}\) 或 \(\{v\}\)。
\(X' \backslash X\) 表示集合的差集,即从集合 \(X'\) 中去除掉在集合 \(X\) 中出现的所有元素后剩下的元素集合。
设想树分解的一个可能的情况是这样的:
- 开始节点:包含 \(\{A, B, C\}\)
- 子节点 1:包含 \(\{B, C, D\}\) (这里 \(A\) 被“遗忘”,因为它不在子节点中)
那么这里的遗忘节点 \(X\) 即是 \(\{B, C, D\}\),因为它是发生顶点遗忘后的结果。而子节点 \(X'\) 是 \(\{A, B, C\}\),因为它是在顶点遗忘之前的状态。
上述引理基本上表明,每条边都可以准确地“分配”给一个遗忘节点。对于遗忘节点 \(X \, (x_2, x_3, ..., x_k)\) 与其子节点 \(C \, (x_1, x_2, ..., x_k)\)【即 \(x_1\) 被遗忘】,本文将 \(x_1, x_2, ..., x_k\) 之间的所有边分配给这个遗忘节点。
动态规划的主要过程
- 首先从图中移除所有边,然后自下而上地遍历 \(TD\)。
- 在遗忘节点 \(X\) 处,首先检查分配给
\(X\) 的所有边。
- 如果一条边不可阻挡或决定不阻挡,则将其重新放入图中。
- 否则,不将其放回。
- 在完成整棵树后(同时确保花费的预算最多为 \(b\),至少放回了 \(|E| - b\) 条边),得到了一个完整的阻挡策略。
设定
设 \(X=(x_1, x_2, ..., x_k)\) 是一个树节点 \((k \le w + 1)\)。
设 \(St(X)\) 是以 \(X\) 为根的树分解 \(TD\) 中的子树。
设 \(Ch(X)\) 是 \(St(X)\) 中引用的所有图顶点的集合。
设 \(Ch(X)' = Ch(X) \backslash X\)。
那么,\(Ch(X)'\) 就是在自底向上处理 \(St(X)\) 后的一个遗忘顶点的集合。树分解的一个已知属性是,\(Ch(X)'\) 中的顶点不能直接到达 \(V \backslash Ch(X)\) 中的任何顶点。也就是说,任何从 \(Ch(X)'\) 中的入口顶点到 \(DA\)(域管理员)的攻击路径都必须经过 \(X\) 中的某个 \(x_i\)。
同样,任何攻击路径(不一定起源于 \(Ch(X)'\))可能通过进入由 \(Ch(X)'\) 形成的图区域(通过某个特定的 \(x_i\)),然后通过不同的节点 \(x_j\) 退出该区域,从而涉及 \(Ch(X)'\) 中的顶点。一个攻击路径可能多次“进入和退出”该区域,但所有的进入和退出都必须通过 \(X\) 中的顶点。
有一个图,它由顶点 \(A, B, C, D, E\) 组成,并且有以下连接:\(A-B, B-C, C-D, D-E\)。现在,对这个图进行树分解。
- 假设有一个树节点 \(X = (B, C)\),这意味着树分解中有一个节点包含图中的 \(B\) 和 \(C\) 顶点。
- \(St(X)\) 就是以 \(X\) 为根的子树,在简单例子中,可以想象它就是包含 \(B\) 和 \(C\) 的部分,可能还会向下包括与 \(B\) 和 \(C\) 直接相连的其他顶点,比如 \(A\) 和 \(D\)。
- \(Ch(X)\) 是在 \(St(X)\) 中引用的所有顶点的集合。在例子中,如果 \(St(X)\) 包括边 \(B-A\) 和 \(C-D\),那么 \(Ch(X)\) 就是 \(\{A, B, C, D\}\)。
- \(Ch(X)'\) 是 \(Ch(X)\) 移除 \(X\) 中顶点后的集合,所以 \(Ch(X)' = \{A, D\}\),这表示在处理完包含 \(B\) 和 \(C\) 的树节点后,\(A\) 和 \(D\) 是“被忘记的”或者说是“不再考虑的”顶点。
现在,根据树分解的性质,\(Ch(X)'\) 中的顶点 \((A,D)\) 不能直接到达图中不在 \(Ch(X)\) 中的任何顶点(比如 \(E\))。这意味着,任何从 \(A\) 或 \(D\) 到达图中其他部分(比如到达 E)的路径都必须经过 B 或 C。
举个具体的例子:
- 如果有一个攻击路径想从 \(A\) 到达 \(E\),这个路径必须经过 \(B\) 或 \(C\)(因为 \(A\) 是通过 \(B\) 连接的,而 \(E\) 是通过 \(D\) 和 \(C\) 连接的)。
- 同样,如果攻击路径在图中的某个点进入了 A 和 D 形成的区域,然后想要离开这个区域去到图的其他部分,它也必须通过 \(B\) 或 \(C\) 进行。
这个引理及其描述的动态规划过程为如何在给定的预算约束下制定有效的阻挡策略提供了一种方法。
通过结构化地处理图中的每条边,可以确保在满足预算限制的同时实现最优的阻挡配置。
在这种情境下,假设在处理树分解中的 \(St(X)\)(即以 \(X\) 为根的子树)时,已经花费了 \(b'\) 单位的预算来“忘记节点”,也就是说,用于阻断与这些被忘记节点相关的边。
关键在于不需要详细记录哪些具体的边被阻断。相反,只需跟踪总共的预算花费以及一个所谓的“距离”矩阵。
这个矩阵用于表示在考虑到已经使用的阻断预算后,图中各顶点之间可达性的变化。
即在执行了一系列阻断操作后,从一个顶点到另一个顶点是否仍然存在未被阻断的路径,以及这些路径的“距离”(路径的长度或者需要通过的边的数量)。
假设有一个小型网络,顶点集合为 \(\{A, B, C, D\}\),目标是阻断攻击者从 \(A\) 达到 \(D\) 的能力。
如果决定花费一定的预算来阻断从 \(B\) 到 \(C\) 的连接(假设这是忘记节点 \(B\) 与 \(C\) 相关的操作的一部分),矩阵需要更新以反映现在从 \(A\) 到 \(D\) 的路径要么变得更长(需要通过更多的边),要么变得不可达(如果没有其他路径)。
因此,即使不记录每一条被阻断的边,通过维护总预算花费和更新“距离”矩阵,仍然能够有效地理解和控制网络的安全状况,尤其是在考虑到预算限制和操作的优化配置时。
这种方法在处理大型或复杂网络时特别有用,它可以更抽象的方式理解网络的安全性,而不是沉浸在繁琐的细节中。
\[ M = \begin{bmatrix} d_{11} & d_{12} & ... & d_{1k} \\ ... \\ d_{k1} & d_{k2} & ... & d_{kk} \\ \end{bmatrix}\quad \]
\[ M = \begin{bmatrix} 0 & 0 & 0 & 0 & 0 \\ 0.05 & 0 & 0.05 & 0.05 & 0 \\ 0.05 & 0 & 0 & 0 & 0 \\ 0 & 0 & 0 & 0 & 0.05 \\ 0.05 & 0.05 & 0 & 0 & 0 \\ \end{bmatrix}\quad \]
\(d_{ij}\) 代表了处理完 \(St(X)\) 后放回的边中,从 \(x_i\) 到 \(x_j\) 的最小路径距离。
当且仅当可以在 \(St(X)\) 上花费 \(b' (b' \le b)\) 来获得距离矩阵 \(M\) 时,则称元组 \((M, b')\) 在 \(X\) 是可能的。
树分解的每个树节点对应一个动态规划子问题,总共有 \(O(wn)\) 个这样的子问题,其中 \(w\) 是树的宽度,\(n\) 是图的顶点数量。
与 \(X\) 对应的子问题表示为 \(DP(X)\),它简单地返回在节点 \(X\) 可能的所有元组集合。
这种方法通过将大问题分解成较小的子问题来解决,每个子问题都是关于树节点的,并考虑在该节点上可实现的所有可能的预算花费和距离矩阵组合。
这样,每个子问题都可以独立解决,并且它们的解可以用来构建整个问题的解。
动态规划的这种方法允许算法有效地遍历整个问题空间,同时避免重复计算已解决的子问题,从而提高了算法的效率。
举个简单的例子,如果在处理某个节点 \(X\) 时发现可以通过花费 \(b'\) 单位的预算来阻断某些边,并且这导致了从一个顶点到另一个顶点的最小路径距离发生变化,那么这个新的距离矩阵和预算花费 \(b'\) 就构成了一个可能的元组 \((M, b')\)。
\(DP(X)\) 的任务就是找出所有这样的可能元组,为进一步的计算和最终解的构建提供基础。
基础设定
- 对于一个叶子节点 \(X = \{x\}\),如果 \(x\) 是一个入口顶点,那么 \(DP(X)\) 包含一个元组,即 \(([0],0)\)。这表示从这个入口顶点到它自身的最小路径距离为 \(0\),且没有预算被花费(因为不需要阻断任何路径)。
- 否则,如果 \(x\) 不是入口顶点,\(DP(X)\) 中唯一可能的元组是 \(([\infty],0)\)。这表示从这个顶点到任何入口顶点(或反之)的距离是无穷大,即不可达,同时没有预算被花费。
原始问题
- 树分解的根是 \(DA\),因此,原始问题则是 \(DP(\{DA\})\),它返回根节点所有可能的元组集合。
- 集合中的每个元组都有形式 \(([d_{DA,DA}], b')\),这表示可以花费 \(b'\) 预算来确保攻击者到达 \(DA\) 的最小路径距离是 \(d_{DA,DA}\)。
- \(DP(\{DA\})\) 中的最大 \(d_{DA,DA}\) 对应于面对最优阻断策略时攻击者的成功率。换句话说,它表示即使在最优的阻断策略下,攻击者也能达到的最远距离。因此,防御的目标是最大化这个距离,以最大限度地减少攻击者成功攻击域管理员的可能性。
引入节点 (Introduce Node)
- 当处理一个引入节点 \(X = (x_1, ..., x_k, y)\) ,其子节点为 \(X' = (x_1, ..., x_k)\) 时,需要从 \(DP(X')\) 中的可能元组出发,生成新的元组,其应该属于 \(DP(X)\)。
- 如果 \(y\) 是一个入口顶点,则 \(d_{yy}=0\);否则当 \(y\) 被引入时,它的所有边尚未恢复,因此它与 \(x_i\) 断开连接,\(d_{yy}=\infty\)。
- 这样,可以在 \(DP(X)\) 中为每个来自 \(DP(X')\) 的可能元组添加了一个新顶点 \(y\),并设置了 \(y\) 到自身的距离。
\[ \begin{pmatrix} \begin{bmatrix} d_{11} & ... & d_{1k} \\ ... \\ d_{k1} & ... & d_{kk} \\ \end{bmatrix}\quad,b' \end{pmatrix} \rightarrow \begin{pmatrix} \begin{bmatrix} d_{11} & ... & d_{1k} & \infty \\ ... \\ d_{k1} & ... & d_{kk} & \infty \\ \infty & ... & \infty & d_{yy} \end{bmatrix}\quad,b' \end{pmatrix} \]
遗忘节点 (Forget Node)
- 对于一个遗忘节点 \(X = (x_2, ..., x_k)\),其子节点为 \(X' = (x_1, ..., x_k)\) ,需要确定如何阻断连接 \(x_1\) 和其余 \(x_2, ..., x_k\) 的边。
- 因为最多有 \(k − 1\) 条边需要阻断,需要简单地检查最多 \(2^{k-1}\) 种阻断选项。
- 对于每个具体的阻断选项(对应于花费 \(b^{''}\)),需要将 \(DP(X')\) 中的元组转换为 \(DP(X)\) 中的元组(如果 \(b'+b''>b\),则新元组被丢弃)。\(d_{ij}^{'}\) 是来考虑新加回的边的更新距离。更新距离需要运行一个全点对最短路径算法,其复杂度为 \(O(k^3)\)。
\[ \begin{pmatrix} \begin{bmatrix} d_{11} & ... & d_{1k} \\ ... \\ d_{k1} & ... & d_{kk} \\ \end{bmatrix}\quad,b' \end{pmatrix} \rightarrow \begin{pmatrix} \begin{bmatrix} d^{'}_{22} & ... & d^{'}_{2k}\\ ... \\ d^{'}_{k2} & ... & d^{'}_{kk} \\ \end{bmatrix}\quad,b' + b'' \end{pmatrix} \]
连接节点 (Join Node)
- 对于一个连接节点 \(X\),它有两个子节点 \(X_1\) 和 \(X_2\)。对于 \((M_1,b_1) \in DP(X_1)\) 和 \((M_2,b_2) \in DP(X_2)\),如果 \(b_1+b_2\leb\),则标记 \((M',b1+b2)\) 为 \(DP(X)\) 中的一个可能元组。
- \(M'\) 是 \(M_1\) 和 \(M_2\) 之间按元素取最小值得到的矩阵。
通过这种递归方式,动态规划算法能够在考虑图的结构和预算限制的同时,逐步构建出解决问题的解空间。
其每一步都精确地考虑了如何通过引入、遗忘或连接操作来更新当前的状态,使得最终能够在树分解的根节点找到原始问题的解。
定理2 TDCYCLE 算法的复杂度为 \(O(H^{2w^2}b^2w^2n)\)
总结动态规划方法。
- 其遵循自底向上的顺序(从树分解 \(TD\) 的叶子节点到根节点)处理。
- 在处理节点时,传播所有可能的元组集合 \((M, b')\)。
- 在引入/连接节点时,遵循预定的传播规则,不做任何阻断决策。
- 在遗忘节点时,从最多 \(w\) 条边中决定哪些边要阻断。
给定一个特定的 \(AD\) 图及其对应的树分解 \(TD\),可以通过动态规划转换为强化学习环境。
这样便出现了一个比动态规划有更好扩展性的随时算法(即强化学习总能产生一个解决方案,这个解决方案可能是最优的,也可能不是,但通常会随着时间改进;另一方面,动态规划无法扩展以处理稍大的树宽度)。
本文提出的转换技术有可能被应用到基于树分解的动态规划中,用于其他组合优化问题。
这表明,通过将传统的动态规划方法与现代的机器学习技术相结合,可以提高处理复杂问题的能力,特别是在那些难以直接通过传统方法解决的大规模问题上。
通过这种转换,可以利用强化学习的优点,如能够处理大规模状态空间和学习复杂策略,从而提高算法的适应性和扩展性。
- 节点排序:本文通过在 \(TD\) 上执行后序遍历来创建节点的顺序,确保在处理父节点之前先处理子节点。这样的顺序保证了在做出决策时已经考虑了所有子节点的信息。
- 传播最佳元组:与传统动态规划中传播所有可能的元组 \((M, b')\) 不同,本文在强化学习训练过程中只传播最佳元组。举个例子,对于一个遗忘节点 \(X\) 和它的子节点 \(X'\),\(X'\) 处的最佳元组被作为观察传递给 \(X\)。然后,基于这个观察来决定在 \(X\) 阻断哪些边。
- 遗忘节点的特定处理:对于遗忘节点 \(X\),如果有 \(k (k \le w)\) 条边需要决定是否阻断,则在强化学习环境中将其视为 \(k\) 个独立的步骤。也就是说,每一步都对单一边做出阻断决策,且动作空间始终是二元的。
- 引入/连接节点的自动处理:对于引入节点和连接节点,由于不需要做出任何决策,强化学习环境会在步骤之间自动处理这些节点。
- 最终奖励设置:设置的最终奖励等同于解决方案的质量。因为强化学习模型的目标是最大化最终奖励,从而找到最优或接近最优的阻断策略。
将特定的 \(AD\) 图转化为强化学习环境后,可以应用标准的强化学习算法来寻找最优阻塞策略。
在转化后,当树的宽度较小时,观察和行动空间都很小。不幸的是,上述转化技术的一个缺点是无法保证有一个小的 episode 长度。
本文可以认为同时保证小的观察空间、小的行动空间和小的 episode 长度是不可能的,除非 \(AD\) 图在规模上相对较小。毕竟,这解决的是一个 NP 难问题。
实验证明,对于较小的 \(AD\) 图,本文能够在 episode 长度可管理的情况下实现接近最优的性能。
对于较大的 \(AD\) 图,episode 长度太长,因此引入以下启发式方法来限制 episode 长度。
- 设 T 为目标 episode 长度,想法是手动选择 T 个相对重要的边,并将未选择的边设置为不可阻塞。
- 在实验中,首先计算将入口节点与 DA 分开的最小割(不可阻塞边的容量设置为大),令最小割中可阻塞边的数量为 \(C\)。
- 如果 \(C \ge T\),则简单地将这 \(C\) 条边视为重要,并将 episode 长度设置为 \(C\)。
- 如果 \(C < T\),则加入距离 \(DA\) 最近的 \(T − C\) 条可阻塞边。
在本文附录中,有一个实验证明基于强化学习的方法并非仅通过探索进行“随机搜索”,它确实能够“学习”以对给定观察做出反应。
在原始方法中,观察包含距离矩阵 \(M\)、已花费的预算 $\(b'\) 以及当前步骤索引。如果用零矩阵或随机矩阵替换 \(M\),那么训练结果会显著下降。
核化
核化是一种常用的固定参数分析技术,它预处理给定的问题实例,并将其转换为一个更小的等价问题,称为内核。
本文要求内核的大小受到特殊参数的限制(而不是依赖于 \(n\))。
如引言所述,对于实际的 \(AD\) 图,大多数节点最多只有一个出边。
- 如果一条边对攻击者没有用处,那么可以在不失一般性的情况下将其移除。
- 如果一条边对攻击者有用,那么通常它是特权提升的。
- 一个节点具有两条独立的特权提升出边是少见的(因为它们通常对应于安全异常或配置错误)。
本文使用 \(SPLIT\) 来表示所有分裂节点(具有多个出边的节点);\(SPLIT+DA\) 来表示在 \(SPLIT\) 中添加 \(DA\);\(ENTRY\) 来表示所有入口节点;引入了一个新参数,称为非分裂路径的数量。
实验表明,这个参数导致了算法在使用两个不同的开源 \(AD\) 图生成器生成的合成 \(AD\) 图上表现异常优秀。
定义 1(非分裂路径)
给定节点 \(u\),假设 \(v\) 是 \(u\) 的一个后继节点。非分裂路径 \(NSP(u, v)\) 被递归地定义如下:
- 如果 \(v \in SPLIT + DA\),则 \(NSP(u, v)\) 是 \(u \to v\)。
- 否则,\(v\) 必须有唯一的后继节点 \(v'\)。\(NSP(u, v)\) 是将 \(u \to v\) 与 \(NSP(v, v')\) 结合的路径。
换句话说,\(NSP(u, v)\) 是从 \(u\) 到 \(v\) 的路径,然后如果 \(v\) 只有一个后继节点,则重复移动到 \(v\) 的唯一后继节点,直到到达分裂节点或 \(DA\)。
使用 \(DEST(u, v)\) 来表示 \(NSP(u, v)\) 的结束节点,因此有 \(DEST(u, v) \in SPLIT + DA\)。
如果非分裂路径至少有一条边是可阻塞的,则称其为可阻塞的。
\(AD\) 图可以被视为以下一组非分裂路径的连接,参数(非分裂路径数量 \(\#NSP\))是这组路径的大小。
\(\{NSP(u, v)|u \in SPLIT \cup ENTRY, v \in SUCCESSORS(u)\}\)
在路径 \(NSP(u, v)\) 上距离 \(u\) 最远的可阻塞边被标记为 \(BW(u, v)\)。\(BW\) 代表“值得阻塞”,这是由于以下引理所导致的。
引理 2
对于纯策略和混合策略的阻挡,永远别在非分裂路径上花费超过一个单位的预算。
对于任何问题实例,存在一个最优的防御策略,即只阻挡来自以下集合的边:
\(BW = \{BW(u, v)|u \in SPLIT \cup ENTRY, v \in SUCCESSORS(u)\}\)
本文介绍了如何通过前述的非分裂路径构建一个非线性规划,然后将其转化为混合整数规划,并使用最先进的混合整数规划求解器进行高效求解。
本文使用 \(B_e\) 来表示在边 \(e\) 上花费的预算单位。
对于纯策略阻挡,\(B_e\) 是二进制的;对于混合策略阻挡,\(B_e\) 在 \(0\) 到 \(1\) 之间。
如前所述,对于 \(e \in BW\),\(B_e \ge 0\),对于 \(e \notin BW\),\(B_e = 0\)。
本文使用 \(r_u\) 来表示节点 \(u\) 的成功率,节点的成功率是从该节点开始的最优攻击路径在当前防御策略(即 \(B_e\))下的成功率;\(c_{u,v}\) 来表示当没有阻挡时非分裂路径 \(NSP(u, v)\) 的成功率,\(c_{u,v} = \prod_{e \in NSP(u,v)}(1−f(e))\),\(c_{u,v}\) 是常数。
本文使用 \(r^*\) 来表示攻击者的最优成功率。 \[C = \{(u, v)|u \in SPLIT \cup ENTRY, v \in SUCCESSORS(u)\}\] \[C^+ = \{(u, v)|(u, v) \in C, NSP(u, v) \; blockable\}\] \[C^− = \{(u, v)|(u, v) \in C, NSP(u, v) \; not \; blockable\}\]
本文有以下非线性规划: \[min \, r^∗\] \[r^∗ \ge r_u \, , ∀u \in ENTRY\] \[r_u \ge r_{DEST(u,v)}·c_{u,v}·(1-B_{BW(u,v)}), ∀(u,v) \in C^+\] \[r_u \ge r_{DEST(u,v)}·c_{u,v}, ∀(u,v) \in C^-\] \[b \ge \sum_{e \in BW}B_e\] \[r_{DA}=1\] \[r_u,r^* \in [0,1]\] \[B_e \in \{0,1\} or [0,1]\]
上述规划最多有 \(O(\#NSP)\) 个变量和最多 \(O(\#NSP)\) 个约束(都不依赖于 \(n\))。
对于纯策略阻挡,可以通过将 \(r_u \ge r_{DEST(u,v)}·c_{u,v}·(1−B_{BW(u,v)})\) 重写为等价的线性形式 \(r_u \ge r_{DEST(u,v)}·c_{u,v}−B_{BW(u,v)}\) 将上述规划转换为一个整数规划。
混合阻断策略
为了达到目的,这里可以将前一节的非线性规划程序转换为一个几乎是线性的程序。
可以观察到,如果在最优混合策略防御下,攻击者的成功率至少为 \(\varepsilon\),那么这意味着防守方永远不希望以严格大于 \(1 - \varepsilon\) 的概率阻挡任何边。
基于这一观察,本文强制要求不以超过 \(1 - \varepsilon\) 的概率阻挡一条边,并在这一限制下求解最优防御策略。
如果最终结果中,攻击者的成功率至少为 \(\varepsilon\),那么这个限制实际上根本不是限制。
如果本文的解决方案表明攻击者的成功率低于 \(\varepsilon\),那么仍然有一个几乎最优的防御策略。
本文设置 \(\varepsilon=0.01\),即对于所有 \(e \in BW\),要求 \(0 \le B_e \le 0.99\),而不是 \(0 \le B_e \le 1\)。
通过上述观察可以将涉及乘法的非线性规划程序转换为几乎是线性的程序。
技巧是将 \(r_u\) 替换为 \(r'_u = −ln(r_u)\),将 \(r'^*\) 替换为 \(r'^* = −ln(r^*)\),将 \(B_e\) 替换为 \(B'_e = − ln(1 − B_e)\),最后将 \(c_{u,v}\) 替换为 \(c'_{u,v} = − ln(c_{u,v})\)。
则变量现在是 \(r'_u,r'^*,B'_e\)。由于自然对数的单调性,可以将之前的非线性规划重写为: \[max \, r'^{∗}\] \[r'^{∗} ≥ r'_u \, , ∀u \in ENTRY \] \[r'_u ≥ r'_{DEST(u,v)}+c'_{u,v}+B'_{BW(u,v)}, ∀(u,v) \in C^+\] \[r'_u ≥ r'_{DEST(u,v)}+c'_{u,v}, ∀(u,v) \in C^-\] \[b ≥ \sum_{e \in BW}(1-e^{-B'_e})\] \[r'_{DA}=0\] \[r'_u,r'^* \in [0,\infty)\] \[B'_e \in [0,-ln(0.01)]\] 不幸的是,上述程序不是线性的,因为预算约束不是线性的。
此外,上述程序甚至不是凸的:由于 \(1 − e^{−x}\) 是凹的,两个可行解的平均值可能会违反预算约束。
迭代 LP 近似启发式算法
可以注意到 \(1 − e^{−x}\) 是增加的,也就是说,只要降低 \(b'\) 的总和,最终将达到一个满足预算约束的情况。
即如果将预算约束重新表述为 \(b' \ge \sum_{e \in BW}B'_e\),这是一个线性约束。
然后可以猜测一个值 \(b'\),然后解决对应的 \(LP\)。
接下来验证 \(LP\) 解是否也满足原始的非线性预算约束。如果是的话,那么这意味着可以增加对 \(b'\) 的猜测(增加 \(b'\) 意味着花费更多预算)。
如果 \(LP\) 解违反了原始的非线性预算约束,那么这意味着应该减少对 \(b'\) 的猜测。
一个好的 \(b'\) 的猜测可以通过从 \(0\) 到 \(−|BW| ln(0.01)\) 的二分搜索获得。
基于 MIP 的近似方法
另一种解决非线性预算约束的方法是将 \(B_e\) 添加回模型中(对于 \(e \in BW,0 \le B_e \le 0.99\))。
这样,预算约束 \(\sum_{e \in BW} B_e \le b\) 又变成线性的了,不过还需要将 \(B_e\) 和 \(B'_e\) 连接起来,因此引入一组新的非线性约束,即 \(B'_e =−ln(1−B_e), e \in BW\)。
函数 \(− ln(1 − x)\) 在一个小区间内接近一条直线。如果 \(x \in [a, b]\),连接 \((a, − ln(1 − a))\) 和 \((b, − ln(1 − b))\) 的直线是 \(− ln(1 − x)\) 的一个上界。表示 \(− ln(1 − x)\) 下界的直线是在区间中点 \(a+b\) 处的切线。
给定一个特定的 \(Be\),可以将 \(Be\) 的区域 \([0, 0.99]\) 划分为多个较小的区间。对于每个区间,有两条直线分别表示 \(− ln(1 − x)\) 的下界和上界。
可以连接这些区域组成 \(g_L(x)\) 和 \(g_U(x)\),它们分别是 \(− ln(1 − x)\) 的分段线性下界和上界。然后将 \(B'_e =−ln(1−Be)\) 替换为 \(B'_e =g_L(Be)\) 或 \(B'_e =g_U(Be)\),分别创建两个不同的混合整数规划程序。
最后使用 Croxton 等人提出的多选模型来实现带有辅助二进制变量的分段线性约束。
当区间足够细时,实验上,所得到的可行防御接近于下界【因此接近于最优】。