论文 Code Generation with AlphaCodium: From Prompt Engineering to Flow Engineering
说是很火,读一下,GitHub 3k star 了。
在自然语言生成中的优化技巧可能并不适用于代码生成任务。
本文提出了名为 AlphaCodium 的代码生成方法,在 CodeContests 上的准确率从 19% 提升到了 44%。
Introduction
对于同一需求,可以解决问题的代码是丰富多样的。
CodeContests 测试集是从 Codeforces 等竞赛编程平台精心整理而来,一个需求包含超 200 种解法。
DeepMind 开发的代码生成系统 AlphaCode,利用了一个专门针对竞赛编程任务微调的网络,它生成了非常多的解决方案(最多可达100万),然后对这些方案进行处理和聚类,并从中选择少数(约10个)提交。尽管 AlphaCode 的结果令人印象深刻,但需要专门为代码导向任务进行微调模型,以及高计算量的支持,使这个方法并不实用。
CodeChain 是另一项针对竞赛编程任务的工作,它通过一系列基于子模块的自我修订来改善大语言模型的代码生成能力。
而本文提出的 AlphaCodium,是一种围绕迭代过程的面向代码的流程。在该流程中,反复运行并修正生成的代码以通过输入输出测试。
AlphaCodium 流程的两个关键要素是:
生成额外的数据,如问题反思和测试推理,以帮助迭代过程;
通过 AI 生成额外的测试用例来丰富公共测试集。提出的流程如图 1 所示,分为两个主要阶段:一个是自然语言推理问题的预处理阶段,另一个是生成、运行并修正代码解决方案以通过已有测试集和 AI 生成测试集的迭代生成阶段。
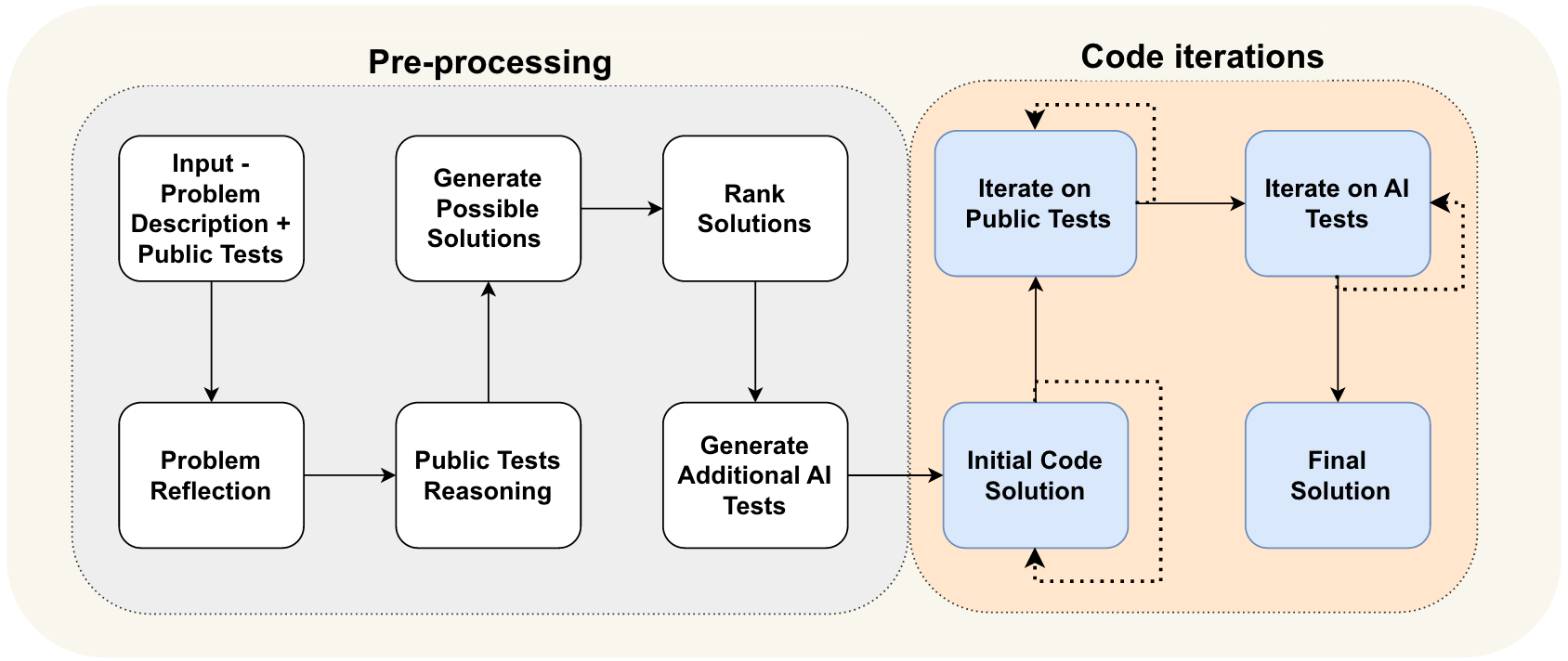
在设计 AlphaCodium 时,本文发现生成额外的有用测试用例比生成正确的代码解决方案更容易。
添加特定测试主要需要理解问题、一些洞察力和基本的蛮力或逻辑推理能力。而在生成额外测试用例时并不需要完全“解决”问题。
AlphaCodium 还利用了一些新颖的面向代码的设计概念、技巧和最佳实践,例如:
- YAML 结构化输出
- 符号分析进行语义推理
- 生成模块化代码
- 双重验证的软决策
- 鼓励探索并放缓决策
- 测试锚点
与精心设计的单一 prompt 相比,AlphaCodium 在 CodeContests 问题上始终显著地提高了大语言模型的性能。
CodeContests Dataset
废话,说明为什么选 CodeContests。
The Proposed Flow
问题反思
描述问题时,列出要点,涵盖问题目标、输入、输出、规则、约束和问题描述中出现的其他相关细节。
公共测试推理
解释每个测试输入如何导致相应的输出。
生成可能的解决方案
生成 2-3 个可能的解决方案列表,用自然语言描述每个解决方案。
排序解决方案
对可能的解决方案进行排序,并选择“最佳解决方案”,考虑正确性、简单性和鲁棒性(不一定选择“最有效”的解决方案)。
生成额外的 AI 测试
为问题生成 68 个多样化的输入输出测试,尽量覆盖原始公共测试未涵盖的情况和方面。
初始代码解决方案
目标是生成一个初步的代码解决方案,使其尽可能接近正确代码,以便在下一阶段的运行修复迭代中更容易成功。阶段流程如下:
- 选择一个潜在的解决方案。生成相应的代码,并在选定的公共和 AI 测试上运行它。
- 重复此过程,直到测试通过或达到尝试限制。
- 第一个通过测试的代码,或输出最接近的代码(见附录 D),将用作下一步的基础代码。
在公共测试上迭代
从基础代码开始,迭代地在公共测试上运行代码。如果代码在特定测试中失败,根据错误信息尝试修复。
在 AI 生成的测试上迭代
在 AI 生成的测试上继续进行运行修复迭代。使用“测试锚点”(见第 4 节)。
Additional insights
AlphaCodium 流程依赖于知识积累,从简单到困难逐步推进,在此过程中逐步获得知识和洞察力,以帮助应对更困难的阶段。
例如,第一个步骤的问题反思的输出可以作为更困难步骤(如生成可能的解决方案)的提示输入。预处理阶段的输出用于帮助最具挑战性和关键的阶段,即代码迭代阶段,本文在此阶段尝试生成正确解决问题的代码。
此外,在设计 AlphaCodium 时,对于 AI 来说,生成更多测试比生成完整的解决方案代码更容易。生成额外的测试主要需要理解问题和基本的暴力破解或逻辑推理。无需完全“解决”问题即可生成额外的有用输入输出测试对。这与生成正确的解决方案代码形成对比,后者需要一个完整的算法解决方案,相当于正确解决所有可能的输入输出测试对。因此可以生成更多的 AI 测试,然后利用这些测试来改进代码创建阶段,如图 1(b) 所示。本文进一步通过要求模型关注原始公共测试未涉及的方面(如大输入、边界情况等)来增强这些额外测试的贡献。
此外,注意到一些步骤可以合并为单次 LLM 调用,并且图 2(a) 中的流程是一个概念流程,强调了过程的高层步骤。在实际应用中,结构化输出(见第 4 节)使得可以将多个阶段合并为单次 LLM 调用,以节省资源,或因为模型在同时处理特定任务时表现更好。
Code-Oriented Design Concepts
YAML Structured output
要求模型生成等效于给定 Pydantic 类的 YAML 格式输出是关键的一部。
Semantic reasoning via bullet points analysis
当要求 LLM 理解一个问题时,要求输出以项目符号格式【一般描述、目标和规则、输入结构和输出结构】呈现通常会获得更好的结果,如图 2。
生成一个单一冗长的函数时,代码通常包含错误或逻辑错误。
单一的整体代码会影响迭代修复的能力。
当明确要求模型将生成的代码划分为小的子函数,具有有意义的名称和功能时,生成的代码更好,错误更少,迭代修复阶段的成功率更高。

LLMs do better when generating a modular code
LLM 在需要思考、推理和做出严格非平凡决策的代码任务中往往表现不佳。
本文添加了一个额外步骤:给定生成的输出,模型被要求重新生成相同的输出,但如果需要则进行修正。
比直接问“这个测试是否正确?”的问题更有效。
Soft decisions with double validation
直接问复杂的问题时,容易看到幻觉和错误答案。
因此采用了逐步数据积累的流程,从简单任务到复杂任务:
- 从最简单的任务开始,对问题进行自我反思,并推理公共测试。
- 继续生成额外的 AI 测试和可能的解决方案。
- 只有在获得模型对上述任务的回答后,才进行实际的代码生成和运行修复迭代。
Test anchors
当测试失败时,如何判断是因为代码错误还是因为测试本身错误?
测试锚点技术:
- 首先在公共测试上进行迭代:这些测试必然是正确的。完成后,将所有通过的测试设置为锚点测试。
- 然后逐个在 AI 生成的测试上进行迭代:如果一个测试通过,将其添加到测试锚点列表中。
- 如果一个测试失败,假设是因为代码不正确,并尝试修复代码。但要求修复后的代码也必须通过所有已获取的测试锚点。因此,测试锚点免受错误修复代码的影响。
Results
结论感觉没啥好看的但蛮记录一下。
Direct prompt vs. AlphaCodium flow
定义指标为 pass@k,定义为每个问题生成 k 个解决方案后成功解决问题的百分比。
对于 GPT-4 的验证集,pass@5 得分从 19% 提升到 44%,提高了 2.3 倍。
Comparison to previous works
当与 CodeChain 使用相同模型(GPT-3.5)和相同指标(pass@5)进行比较时,AlphaCodium 的表现始终更优。
算了懒得记了反正就是说他好,差的也不会拿来比。
Conclusions
总结一下,本文提出的流程分为两个主要阶段:
- 预处理阶段:AlphaCodium 以自然语言推理问题。
- 代码迭代阶段:AlphaCodium 在公共测试和 AI 生成的测试上进行迭代。
还采用了额外的设计理念、技巧和最佳实践,这些对代码生成非常有帮助,包括:
- 使用 YAML 格式生成结构化输出。
- 生成模块化代码。
- 通过要点分析进行语义推理(semantic reasoning via bullet point analysis)。
- 采用双重验证的柔性决策(soft decisions with double validation)。
- 鼓励探索(encouraging exploration)。
- 测试锚点(test anchors)。