论文 CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis
代码仓库:https://github.com/salesforce/CodeGen
感觉全文都在说的就是多轮交互生成代码。
大篇幅描写的内容都是他自创的评估方法。
考个公吧要不。
Introduction
两个挑战:
- 搜索空间的棘手性
- 难以正确理解用户意图
提出了一种多轮代码生成方法,用户与合成系统进行交流的时候,使用自然语言逐步提供规范,同时接收来自系统以合成子程序的形式作出的响应,这样,用户与系统就可以分多个步骤完成程序。
- 把复杂方法拆解成多个简单步骤
- 利用生成带有注释的代码,反过来增强模型在多轮迭代中的代码生成能力,但这需要大量的数据规模
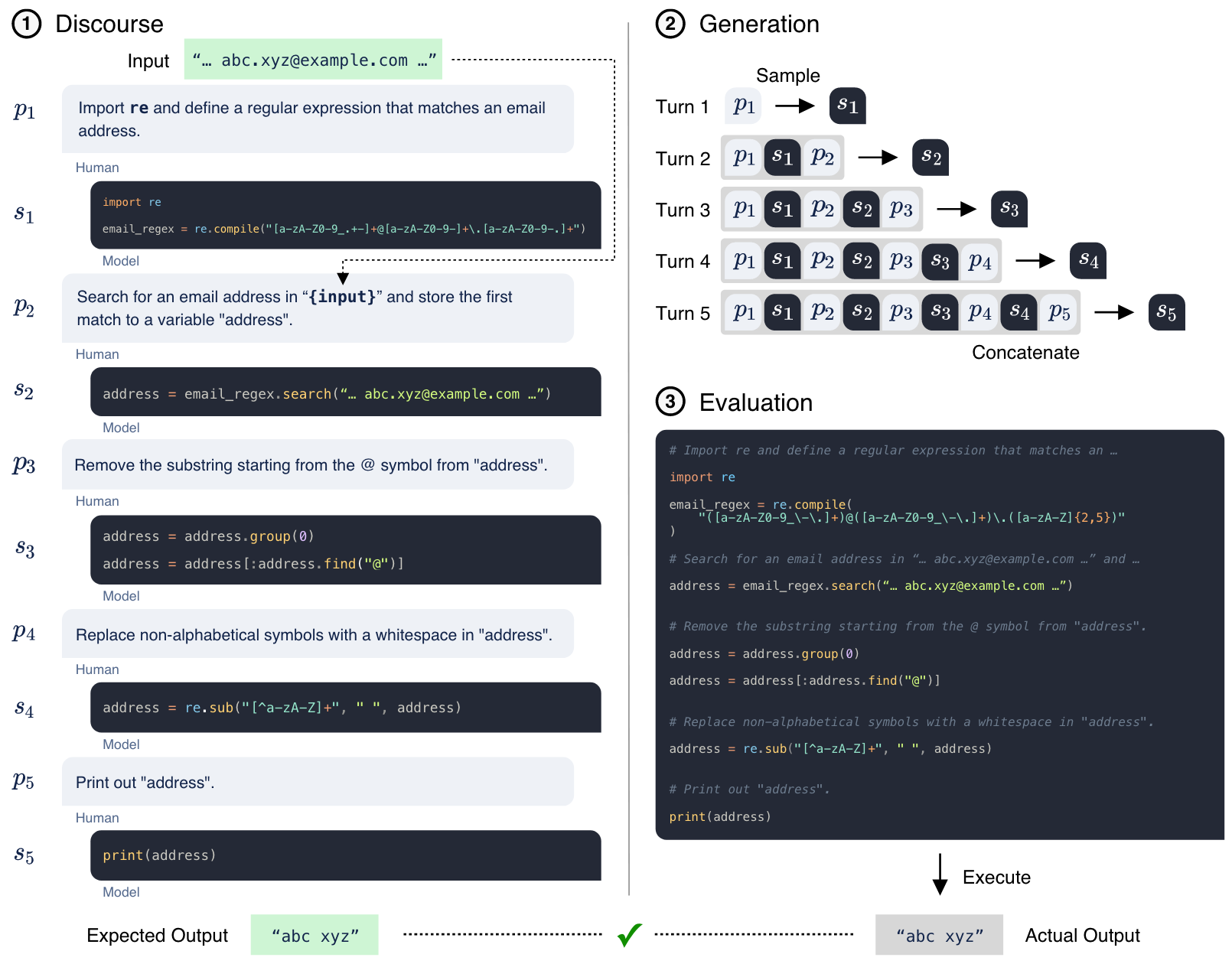
模型通过多步自然语言的描述来生成代码。如图 1,其中展示了模型如何生成一段以提取电子邮件地址的用户名。
基准的表现通过专家编写的测试用例的通过率来衡量。
Model Training
评估多轮编程能力在模型规模扩展下的表现【说实话我没懂什么是 scaling laws,随着模型参数数量和训练数据规模的增加?】。
采用了基于标准 Transformer 架构的自回归语言模型,调整了两个关键变量:
- 模型参数数量
- 训练语料中的编程语言标记数量
为了支持这些大规模模型的训练,作者开发了一个名为 JAXFORMER 的定制库,该库专门用于 TPU-v4 硬件。
Datasets
- THEPILE
- BIGQUERY
- BIGPYTHON
Models
模型在数据集上的训练顺序如上排序。
作者发现,尽管没有针对注释和代码进行训练,但模型依然可以认清二者的关系,他们称这个现象为 “Emergence”,其不仅限于代码生成,也出现在许多自然语言处理任务中。
一些大规模的无监督语言模型可以在零样本的情况下,仅凭对大量数据的训练,就能解决以前从未见过的任务(zero-shot generalization)。
Single-Turn Evalution
作者首先使用现有的代码生成基准测试 HumanEval(MIT许可)来评估 CODEGEN 模型。
HumanEval 包含 164 个手写的 Python 编程问题。
每个问题提供了一个包含函数生成描述、函数签名以及以断言形式给出的示例测试用例的提示。
模型需要根据提示完成一个函数,使其能够通过所有提供的测试用例,从而通过功能正确性来衡量性能。
由于用户意图在单个提示中指定,并且仅提供给模型一次,因此将 HumanEval 的评估视为单轮评估,以区别于下一节中介绍的多轮评估。
作者使用了核采样(Holtzman 等人,2020)的方法,并设置 top-p 参数为 0.95。
HUMANEVAL PERFORMANCE SCALES AS A FUNCTION OF MODEL SIZE AND DATA SIZE
将模型与 Codex 模型(Chen et al., 2021)进行比较,后者在 HumanEval 基准测试中展示了最先进的性能。
Python 程序生成能力会随着 Python 训练数据量的增加而增强。几乎所有的模型,其规模的增加都会提升整体性能。
最大模型 CODEGEN-MONO 16.1B 的性能具有竞争力,并根据 k 的取值在某些情况下超越 Codex。
BETTER USER INTENT UNDERSTANDING YIELDS BETTER SYNTHESIZED PROGRAMS
将所有问题分为“通过”和“未通过”两类。
一个“通过”问题是指至少有一个来自 200 个样本的程序通过了所有的测试用例,
而一个“未通过”问题是指 200 个样本中没有任何一个通过所有测试用例。
计算了“通过”问题和“未通过”问题的平均提示困惑度,基于 CODEGEN-MONO 模型的样本进行分析。结果如表 2 所示。

可以看到,“通过”问题的提示困惑度低于“未通过”问题的提示困惑度。这一发现表明,当模型更好地理解用户意图规格时,代码生成更有可能成功。
事实上,一些训练数据包含了交替出现的自然语言注释和程序,其中注释描述了后续程序的功能。
因此,本文推测,与这种模式相似的用户意图规格更容易被模型理解,从而促成更好的代码生成。受到这一模式的启发,本文提出将用户意图分为多轮提示,使模型每次集中处理部分问题,从而使模型更容易理解用户意图。
MULTI-TURN EVALUATION
在这一部分,本文提出并研究了一种多步骤代码生成范式,其中代码生成被分解为多个步骤,系统在每个步骤合成一个子程序。
为了验证这一范式,本文首先开发了一个多轮编程基准(MTPB)。
MTPB 包含 115 个由专家编写的问题,每个问题都包括多步骤的自然语言描述(提示)。
为了解决一个问题,模型需要合成功能正确的子程序:
- 根据当前步骤的描述合成子程序;
- 考虑到前一步骤的描述和已合成的子程序(例如,正确地回溯引用前一步骤中定义的函数和/或变量)。
图 1 中给出了一个示例。
BENCHMARK CONSTRUCTION
本文首先定义了 115 个问题,这些问题需要广泛的编程知识,包括数学、数组操作、字符串处理、算法、数据科学以及其他需要知识的问题,确保每个类别的问题数量大致平衡。
对于每个问题,本文构建了一个三元组,包含多轮提示 P、测试用例输入 I 和测试用例输出 O。
多轮提示 P 设计遵循两个约束条件:
(1)问题被分解为 3 个或更多步骤,
(2)单轮提示不能完成整个问题的解答。
例如,实施线性回归模型可以表达为“对 x 和 y 进行线性回归”。
由于主要任务在此提示中已完全表达,理解该提示足以执行任务。本文通过人工检查避免了这种情况,并将问题解决过程分布到多个步骤中。
与提示一起,本文要求问题的作者准备 5 组测试用例输入 I 和输出 O,以评估模型输出的功能正确性。
为了避免错误奖励那些通过测试但给出无意义程序的错误正例,本文审查并修订这些案例,以确保测试质量。
与 HumanEval 中期望模型完成部分定义函数的方式不同,MTPB 问题仅提供提示,因此模型必须从头生成解决方案。
虽然自由格式的生成可能允许更多潜在的解决方案,但缺乏提供测试用例输入的入口使得测试生成的代码在多样化测试用例中的表现更加困难。
为了解决这一挑战,我们在提示中嵌入了测试用例输入。
具体来说,提示使用 Python 的格式化字符串书写,在应用特定的测试用例时,输入值会替代变量名。
例如,一个 prompt 如下:
定义一个名为 ‘s’ 的字符串,值为 {var}。
当测试用例输入为 var = 'Hello' 时,格式化为
定义一个名为 ‘s’ 的字符串,值为 'Hello'。
图 1 中也给出了一个例子。
EXECUTION ENVIRONMENT AND SOLUTION EVALUATION
在执行过程中,提示和生成的完成对的历史记录会被连接成一个自包含的程序(见图 1 中的 3)。
然后,该程序将在隔离的 Python 环境中执行,遵循单轮 HumanEval 基准(Chen et al., 2021)。
HumanEval 中的问题是通过完成已知的函数签名来构建的,因此在一组功能单元测试下调用生成的代码是简单的。
MULTI-TURN EVALUATION 中不保证会生成这样的入口点(或返回值),因此最后一个提示总是指定打印出结果状态到终端。
然后,基准执行环境会重载 Python 的 print(args) 函数并将
args 存储在堆栈中。
如果问题的最后一个提示生成的代码不包含 print()
语句(这是在 Python 或特定的 Jupyter notebooks
中打印到终端的有效约定),则会修改生成代码的 AST,注入
print() 的调用。
MULTI-STEP PROGRAMMING CAPACITY SCALES WITH MODEL SIZE AND DATA SIZE
研究了模型规模和数据规模如何影响多轮范式下的代码生成能力。
MTPB 上的表现随着模型规模和数据规模的增加而提高。
这表明,多步骤代码生成能力随着模型规模和数据规模的增加而提升。
模型仅通过自回归语言建模目标进行训练。
在模型和数据规模扩大时,多轮代码生成能力应运而生,也就是在多轮方式下代码生成能力。
BETTER USER SPECIFICATION UNDERSTANDING WITH MULTI-TURN FACTORIZATION
本文假设多轮分解可以增强模型对用户意图规格的理解,从而提高代码生成能力。
为了验证这一假设,本文通过将每个多轮规格合并成一个单轮规格,形成一个单轮版本的对照组。
实验结果表明,对于所有模型,单轮规格的平均困惑度高于多轮规格。
较大模型下的多轮和单轮意图规格的平均困惑度略低于较小模型下的困惑度,表明较大的模型比较小的模型更能理解用户意图。
这与本文最初的假设一致,即将复杂的规格分解能够简化问题理解并提升代码生成能力。
QUALITATIVE EXAMPLES
总体而言,较大规模的模型克服了较小模型由于误解提示而产生的错误。
CONCLUSION
本文研究了基于大规模代码数据语料库训练的大型因果语言模型在代码生成中的应用。
随着模型规模和数据规模的增加,理解长上下文并生成连贯响应的能力从简单的语言建模中自然涌现。
利用这一能力,并且观察到更好的用户意图理解能够带来更优的代码生成,本文提出了一种多步骤的代码生成方法,其中代码生成通过多轮的意图说明和代码生成实现。
此外,本文开发了多轮编程基准(MTPB),以研究本文的模型在这种多步骤范式下代码生成能力。
本文的实验表明,多步骤代码生成的能力随着模型规模和数据规模的增加而提升。
多步骤指定的意图说明能够更容易地被模型消化,从而带来更准确的代码生成。
为了促进未来在这一领域的研究和实际应用,本文将训练代码和模型检查点开源。