论文 Efficient Detection of Java Deserialization Gadget Chains via Bottom-up Gadget Search and Dataflow-aided Payload Construction
阅读笔记,2024 S&P。
摘要
Java 反序列化中一个众所周知且严重的安全漏洞是 Java 对象注入(JOI),它使得远程攻击者能够注入一个精心制作的序列化对象,触发一系列内部 Java 方法(称为 gadgets),最终实现一系列严重的攻击后果,例如远程代码执行(RCE)和拒绝服务(DoS)攻击。
研究内容
本文设计并实现了一种新颖的 Java 反序列化 gadget 检测框架,称为 JDD。
通过自下而上的方法解决了静态路径爆炸问题:首先寻找 gadget 片段,然后从接收器到源链 gadget 片段。该方法将最大静态搜索时间从指数级降低到多项式级,即从 \(O(eM^n)\) 到 \(O(M^2n^3 + enM)\),其中 \(n\) 是 gadget 链中动态函数调用的数量,\(M\) 是动态函数调用候选的平均数量,\(e\) 是入口点的数量。
更重要的是,JDD 能够重用在先前漏洞中发现的现有 gadget 片段,进一步加快了搜索过程。
构建了所谓的注入对象构建图(Injection Object Construction Diagram),该图模拟了注入对象 Field 之间的数据流依赖关系,以促进动态 fuzzing,丰富 payload 中的细粒度对象关系。
这个 Injection Object Construction Diagram 在后面的系统设计中有提到。
概述
JOI 漏洞的利用需要以下两个条件:
- 一个执行路径,可以在反序列化过程中调用可以执行恶意代码(或上传任意文件、拒绝服务等)的安全敏感方法,称为 gadget 链。
- 一个驱动 gadget 链执行的序列化对象,称为注入对象。
因此,JDD 有两个主要的检测目标:
- 使用静态分析找到潜在的 gadget 链。
- 动态生成可利用的注入对象以验证 gadget 链的可利用性。
以下是 JDD 在 sofa-rpc 中发现的一个 0day gadget 链。
第 4 行开始执行了一个 put() 方法,然后不停调用。
一直到第 54 行执行了 invoke() 方法完成反序列化。

以下是攻击者的利用链。
第 15–18 行创建了两个相同 hashCode 的 NodeImpl,为了触发 equals() 方法【gadget 中的第 7 行】。
第 12/13/19 行创建了 ConcurrentHashMap 并赋值,是为了调用 gadget 中的第 27 行。
第 2/20 行的赋值是为了调用 gadget 中的第 36 行。
最后 4-10 行是指定了远程加载动态代码的参数,攻击调用点在 gadget 中的第 54 行。

挑战 I:静态路径爆炸
第一个挑战是对于以往自上而下的搜索来说,起始点和结束点之间所有可能路径的数量是指数级的,且有时候由于方法名相同会导致冗余,导致路径爆炸。
以图 1 为例:
- Fragment I 和 II 之间的 equals() 方法的潜在候选数量可能为 \(2,751\),对 II 和 III 之间的另一个 equals() 方法也适用。
- 然后,在 III 和 IV 之间的 get() 方法的候选数量为 \(148\)。
- 在 IV 和 V 之间的 createValue() 方法为 \(12\)。
解决方案
因此,如果使用深度优先搜索(DFS)来找到像 ODDFuzz 所做的 gadget 链,总执行路径数量可能为 \(2751×2751×148×12 = 13,440,769,776\),这几乎不可能。
对此 JDD 一次性分析所有可能的 gadget,形成片段,然后自下而上从结束点到起始点链接所有的片段,形成链。
具体来说,JDD 只需要分析 \((12 + 2751 + 148) = 2,911\) 个程序执行路径,并且在最多分析 $ (2911×2911 - 2751×2751 - 148×148 - 12×12)×2 + 2751 = 1,770,495$ 次片段链接,这仅仅是自上而下方法的 \(0.01\%\)。
挑战II:并行和嵌套的注入对象结构
第二个挑战是负载,即注入对象,可能具有复杂的结构,例如嵌套或并行对象。
下图显示了图 1 中示例的注入对象结构。
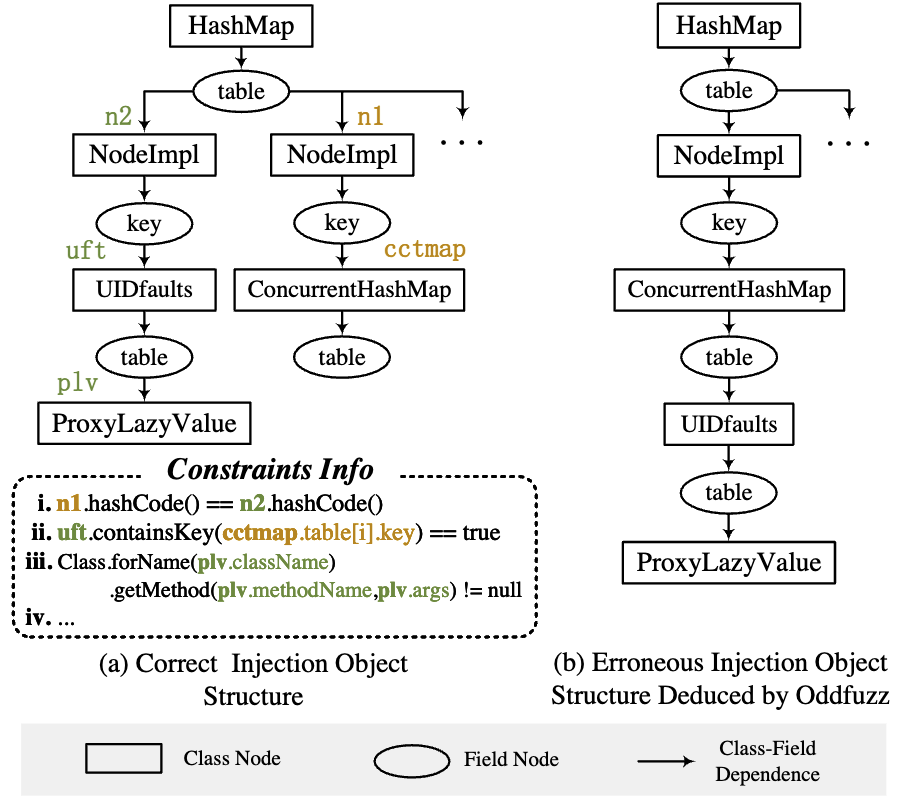
UIDfaults 和 ConcurrentHashMap 是正确 payload 中 NodeImpl 对象下的两个 key。
然而,先前的工作,如 ODDFuzz,仅考虑从 gadget 链推断出的类层次结构,因此它们将生成一个错误的对象结构,如 b 所示,因为在 ConcurrentHashMap 之后调用了 UIDfaults 的 get() 方法【图 1 中的第 27 行】。
解决方案
本文使用了数据流辅助注入对象构建图(Injection Object Construction Diagram)。
关键观察是不同的注入对象,例如它们的 Field ,通过数据流连接。
具体来说,图 1 中不同颜色的两条虚线显示了两个这样的数据流。
key(第 8 行)流向 this.key(第 17 行),然后流向 this.table[index].key(第 27 行)。
然后,p.key(第 8 行)流向 ((NodeImpl) obj).key(第 17 行),然后流向 (Map<?,?>)o(第 27 行)。
因此推断出有两个 NodeImpl 对象,UIDfaults 位于一个 NodeImpl 对象的键下,而不是 ConcurrentHashMap 的 table 下。
设计
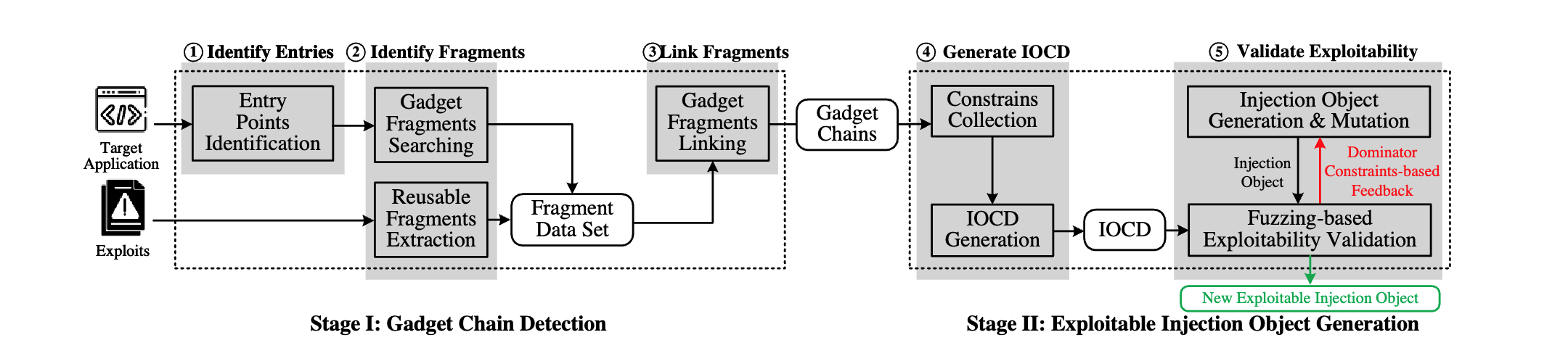
系统架构
Stage I
从识别 sofa-rpc 中的入口点开始,然后将它们用作开始静态污染分析的起始点。
从每个入口点开始遍历目标程序的控制流和数据流图,直到动态方法调用,并将其视为一个片段。
然后,将动态方法的实现视为新的起始点,直到下一个动态方法调用,并将两者之间的代码视为新的片段。
在此过程中,JDD 识别包含结束点的一些 gadget 片段,如图 1 Fragment V 中的 MethodUtil.invoke()。
接下来,在步骤 3 中,使用该片段查找有动态调用 LazyValue.createValue() 方法的 Fragment IV,以及根据先前的污染分析结果查找调用 createValue() 方法的对象的值。
随后,将 Fragment IV 作为新的起点来查找 Fragment III,并重复此过程,直到到达起始点,形成一个 gadget 链。
连接片段 Fragment IV 后,为了完成 gadget 链,JDD 将独立收集可能导致攻击者 RCE 的潜在片段,例如包含 JNDI 功能的 Fragment VI。
由于 Fragment V 具有反射功能,并且参数由攻击者控制,因此 JDD 将进一步将其连接。
Stage II
在步骤 4 中,JDD 提取 gadget 链链接的约束,其中包括如下:
- 结构化约束(即对象和 Field 实例之间的类层次关系)。
- Field 依赖约束(对于示例,n1.key 和 n2.key 的 hashCode 应该相同)。
- 条件分支。
需要注意的是,JDD 将不同执行路径共享的约束标记为支配者(dominator),这意味着它们被所有执行路径所需。
在提取这些约束后,JDD 使用一种称为 Injection Object Construction Diagram 的新数据结构来模拟对象 Field 之间的数据流依赖关系,并指导动态模糊测试。
最后,在步骤 5 中,JDD 仪器化目标程序的收集约束,并使用覆盖支配者约束的数量来指导模糊测试,以生成一个可以利用该 gadget 链的注入对象。
具体来说,JDD 首先根据 Injection Object Construction Diagram 图中的类层次结构初始化一个实例对象。然后,为对象中的每个 Field 分配适当的值,JDD 使用约束求解器解决支配者约束。最后,JDD 使用此对象作为种子来驱动定向模糊测试,并利用覆盖的支配约束数量来评估其效能。
步骤 1:识别反序列化入口点
入口方法有两类:
- Java 语言提供的反序列化方法,例如 readObjectNoData()、readExternal() 和 readObject()。
- Java 反序列化协议提供的接口,例如 Hessian 协议的 Map.put()。
需要注意的是,由于许多这些入口点被定义为接口,JDD 进一步识别和分析它们的覆盖或实现方法作为入口点。
步骤 2:使用静态污染分析识别 gadget 片段
两个子步骤:
- gadget 片段形成。
- 在片段内的数据流分析。
首先,将入口点或先前动态方法调用的实现,直到下一个动态方法调用,将其中的代码视为一个片段。
其次,还执行数据流分析,记录片段中第一个方法的参数传播的污染。
具体来说,本文设计了一个基于片段的摘要,对于每个 gadget 片段,记录其第一个方法和最后一个方法参数之间的污染行为,并维护一个可到达的终点的记录。
本文将方法之间的跳转转换为 gadget 片段之间的跳转,目的是灵活模拟动态方法调用并减少方法之间搜索的计算复杂性。
Gadget 片段定义
对于每个片段,其终点通常是一个安全敏感的方法或指向另一个片段的动态方法调用,例如 Object.equals() 可以连接到几乎所有实现了 equals() 方法。
在反序列化过程中,这种动态方法调用确实导致了程序执行方向的存在多种可能性,它们就像 jump/goto 指令一样。
具体来说,gadget 片段中的方法具有:
- 头部,这是该片段的入口方法,并存在一些动态方法调用可以跳转到该方法。
- 终点,这是该片段的退出方法,通常是一个动态方法调用或安全敏感的方法。
- 其他 gadget,这些是非动态方法,在反序列化过程中按顺序执行,以连接头部和终点。
Gadget 片段的动态方法调用类型
多态调用
JDD 识别目标程序类的继承层次结构,并识别重写的方法。然后,当父类中的方法被调用时,JDD 将其连接到其子类实现的相应重写方法。
例如,考虑一个类 B 重写了类 C 的方法 m(),任何以 C.m() 为终点的片段都可以跳转到其他以 B.m() 为头的片段。
动态代理
Java 语言支持以接口、Object 和其他泛型为类型的对象实现为动态代理实例.
当实例调用任何方法时,它将被重定向到特定的调用处理程序,即在此代理中实现的 invoke() 方法。
这种处理程序通常基于触发方法的属性(例如方法名称)部署方法路由。
因此,对于每个处理程序,JDD 执行路径敏感分析以了解其方法路由,以确保触发方法不会连接到错误的执行路径。
在实践中,JDD 首先在调用处理程序的所有执行路径中识别 Gadget 片段,并根据其执行路径为相应的方法属性要求标记 Gadget 片段。
反射
与其他动态特性不同,Java 反射可以根据其参数调用程序中几乎所有的方法。
JDD 首先检查反射的参数是否受攻击者控制,然后限制其连接包含代码执行能力的片段。
请注意,JDD 允许反射将任何 Gadget 片段连接到其后续片段,但更倾向于两种类型的 Gadget 片段:
- 没有参数的方法,特别是 getter 或 is 方法,和接口方法的实现。
- 带有布尔或字符串类型的一个参数的方法。
步骤 3:使用自下而上的方法链接 Fragment 片段以构建 Gadget 链
首先,JDD 获得了 3 个类型的 Fragments。
- Source Fragments,其头部是一个源,例如 Figure 1 中的 Gadget Fragment I。
- Free-State Fragments,记录了两个动态方法调用之间的方法执行顺序,例如 Figure 1 中的 Gadget Fragment II-IV
- Sink Fragments,其结尾是一个结束点,例如 Figure 1 中的 Fragment V、VI。
然后将 Sink 连上 Free-State,最后连上 Source。
但是 JDD 需要考虑不同的动态调用对应的污染条件和调用条件,比如 Sink Fragments 一般有特定参数可以被攻击者控制。
算法 1 中的细节如下:
首先,JDD 连接了可以过渡到 Sink Fragments 的 Free-State Fragments。
如算法 1 所示,在每一轮中(第 2-19 行),JDD 遍历了 Free-State Fragments \(frag_fs\)。
基于 \(frag_fs\),JDD 检查其链接到 Sink Fragments 是否满足条件。
如果满足,\(frag_fs\) 将作为下一次迭代的 Sink Fragments(第 8-9 行)添加到 new Sink Fragments 中,同时跟踪污点需求以满足连接(如果它们与已记录的污点需求相同,则合并它们)(第 11 行)。
由于每次迭代都可以找出所有可能连接到当前 Sink Fragments,如果这些片段不是 new Sink Fragments 则终止迭代,即当 new Sink Fragments 为空时(第 15-16 行)或达到最大搜索尝试次数时。
接下来,遍历 Source Fragments,并采用相同的方法检测可连接的后继片段,从而获得所有潜在的片段链(第 20-26 行)。

最后,假设有 n' 个不同的动态方法调用。
为什么最大迭代次数的上限是n'。
如果迭代次数超过 n',最长的片段必然包含两个结尾相同的片段,其动态方法调用相同。
由于攻击者有能力调用具有相同动态方法调用的任何候选项,攻击者可以直接提供后一个调用中的类实现以减少总长度,因此两个相同动态方法调用之间的路径是冗余的。
时间复杂度
根据以下定理 1 和 2,JDD 将静态搜索时间从 \(O(eM^n)\)(即现有技术,如ODDFuzz) 减少到 \(O(M^2n^3 + enM)\)。
定理 1
算法 1 的搜索复杂度是 \(O(M^2n^3 + enM)\),其中 \(n\) 是动态方法调用的数量,\(M\) 是这些调用的候选项的平均数量,\(e\) 是入口点的数量。
定理 2
ODDFuzz 的搜索复杂度是 \(O(eM^n)\),其中所有符号都遵循定理 1。
步骤 4:根据注入对象相关约束建立 IOCD
两个步骤:
- 约束提取
- 基于注入对象相关约束的 IOCD 生成
首先,JDD 遵循这个 gadget 链的调用序列来提取执行路径,然后发现影响输入的三种类型的约束:
Object 和 Field 实例之间的层次关系
对于每个 Fragment,JDD 首先使用数据流分析来确定哪些 Fragment 与下一个 Fragment 链接,然后使用后续 Fragment 的头部方法确定 Field 的实际类型。
比如图 1 中第 3 行,HashMap 对象具有一个 Field table。
但是有一些定义的是通用类型或者 Object,因此 JDD 会继续向下追踪。
比如图 1 中,key 将 Fragment I 连接到 II,obj.key 和 this.key 将 Fragment II 连接到 III,Fragment III 将 Fragment IV 连接到 IV。
与 Field 相关的条件分支
JDD 标记在不同的执行路径中共享的约束为 dominator,这意味着所有执行路径都需要满足这些约束。
在数据流跟踪过程中,JDD 同时通过识别受 Field 影响的变量来收集与 Field 相关的条件分支约束。
此外,为了确保程序执行不会触发异常,还应满足一些隐式约束。
例如,在调用某些方法时, Field 不能为 null。另一个例子是强制类型转换,它要求 Field 应是特定类型的实例。
Field 依赖约束
其中包括 Field 之间的条件约束,如图 3 中所示的约束 i-iii。
需要注意的是,sink 点通常要求特定 Field 由攻击者控制以注入 payload。
JDD 将标记这些 Field 以检查它们是否可以被输入污染。
为了找到 Field 依赖性约束,通常情况下,JDD 会过滤影响多个 Field 的条件约束,然后将这些 Field 标记为相关约束的 Field 依赖。
此外,JDD 还考虑了 Java 反射的特定要求。
例如,在 Java 反射中使用的三个 Field className、methodName 和 args 应确保目标类包含目标方法。
注入对象构造图
在提取这些约束之后,JDD 使用一种新的数据结构,称为注入对象构造图(IOCD)来建模对象结构和 Field 的依赖关系。
有两个子步骤:
JDD 将包含在 gadget 链中的实例化对象视为 ClassNodes。每个ClassNode 存储以下信息:类名和相关的 FieldNodes,表示在反序列化过程中可能使用的 Field 。另一方面,FieldNode 存储这些 Field 的相关约束信息,并标记这些约束是否可以静态确定为 dominator。
根据结构约束,通过 FieldNodes 将 ClassNodes 相互连接,从而指示实例化对象之间的层次关系。
例如,在示例中,JDD 将构造 ClassNodes 表示 NodeImpl、UIDfaults 和 ConcurrentHashMap 的实例。然后,根据结构约束,JDD 将从 UIDfaults 和 ConcurrentHashMap ClassNodes 建立到 NodeImpl ClassNode 的相同 FieldNode(即 key)的边,这意味着至少存在两个 NodeImpl 实例。因此,JDD 将包含一个额外的 NodeImpl ClassNode 来表示两个 NodeImpl 实例的存在,其中每个实例的 Field key 分别分配给 UIDfaults 和 ConcurrentHashMap 实例,如图 3(a)所示。
步骤 5:IOCD 增强方向性模糊测试
具体来说,首先基于 IOCD 生成初始种子,然后使用它们来驱动模糊测试。
在方向性模糊测试的探索阶段,JDD 利用覆盖的 dominator 约束的数量来评估种子的能效,并引导 fuzzer 覆盖更多的 dominator 约束,直到达到 sink 点。
在方向性模糊测试的利用阶段,JDD 仅变动与 sink 点相关的 Field。在每个 Field 的变动过程中,根据 IOCD 调整其他相关 Field,以修复基于 IOCD 的跨 Field 依赖关系。
基于 IOCD 的种子生成
考虑到 Cross-Field 依赖和嵌套对象结构,JDD 使用基于 IOCD 引导的 fuzzer ,并考虑 Field 之间的约束来生成正确类层次结构的对象。
具体来说,基于 IOCD 从 ClassNodes 生成无参数实例,并根据有向边建立这些实例的类层次结构,如图 3 所示。
随后,从根 ClassNode 节点开始,在每个 FieldNode 上执行广度优先遍历。
JDD 将提取这些 FieldNodes 的 dominator 约束,并调用约束求解器生成适当的值,然后将这些值分配给相应的 Field 。
当双向边存在 FieldNodes 之间的时候,表示两个 Field 之间存在约束依赖关系,JDD 会从相关 FieldNodes 提取 dominator 条件约束。
然后,使用约束求解器解决这些约束,以找到同时满足这些约束的值。
依赖感知种子变动
IOCD 从以下三个方面显著提高了模糊测试的效率:
- 选择适当的 Field 进行变动。
- 通过约束信息减少不确定的变动空间。
- 考虑 Field 之间的依赖关系和嵌套对象结构。
在变动 Field 时,需要考虑到该 Field 与其他相关 Field 或包含该 Field 的上级实例对象之间的约束关系。详细策略可在表 2 中找到。

基于条件约束的变动
首先,根据种子执行获取的反馈信息,JDD 匹配来自 IOCD 的适当条件约束,这些约束是从指定程序执行流程中导出的 gadget 链。
然后利用这些条件约束来有选择性地指导注入对象的结构变动。
为了记录所选的条件约束策略,JDD 定义了一个唯一标识符,并分配一个 2 位标志来指示每个条件约束的变动策略。
第一位用于指示约束是否被使用(0:未选中,1:选中),第二位表示约束是否满足(true or false)。
有了这个标识符,JDD 更倾向于选择未使用的策略,以涵盖更多种类的条件约束组合。
以下是如何基于反馈信息生成条件约束分支策略的解释:
- 如果 JDD 解决了 ClassCastException 或 NullPointerException 异常信息,则可以根据错误位置信息(类名、代码行号)从 IOCD 中匹配引起异常的相关 Field ,并要求这些 Field 满足特定的约束,即 \(field \; != \; null,field \; instanceof \; X.class\)。
- 提取当前达到的条件约束和下一个 dominator 条件约束之间的所有约束,并根据每个约束的标识符选择变动策略。
- 如果当前和下一个 dominator 条件约束之间没有非 dominator 条件约束,则为当前 dominator 和前面的条件约束选择随机变动策略,注意 dominator 条件约束不改变第二位标志。
- 如果程序已达到汇合点但未触发预期的恶意指令,则 JDD 首先检查是否存在多种构造恶意数据的方法(即从不同 Field 构造)。如果存在这样的变化,JDD 使用 IOCD 中记录的信息调用不同的 Field 来构造恶意数据。否则,随机更改条件约束策略。
- 如果已使用所有条件约束策略的组合,则为从未标记为现有条件约束的 IOCD 中随机选择的 Field 分配 50% 的概率进行变动。
- 当程序到达汇合点并捕获到写入的恶意指令时,这意味着注入对象是可利用的,并且相应的片段链被归类为可利用。如果超过了时间阈值,或者根据上述特定类型的信息,可以直接确定为不可利用,当前测试将终止,并且将调用下一个 IOCD 来对应下一个片段链,以开始新一轮的测试。
基于对象结构约束的变动
在获得条件约束之后,JDD 调用约束求解器来调整对象的结构。
然而,正如 IOCD 所示, Field 之间存在复杂的约束关系。
修改其中一个 Field 不仅会影响相应的 ClassNode,还会影响其 Field 以及与其他 ClassNode 关联的 Field 。
因此,仅基于条件约束对单个 Field 进行简单调整可能会损害对象的结构有效性。
为了解决这个问题,本文提出了级联变动策略。
当 JDD 调整一个 Field 时,它会级联地检查受此 Field 影响的其他 Field 是否也需要调整。
如果需要,它会同时调整它们,以保持注入对象的结构有效性。
具体来说,变动策略可以分为两个级别:单 Field 和跨 Field 。
- 单 Field 级别。变动单个 Field ,该 Field 与其他 Field 没有任何约束。利用约束求解器来解决相关的条件约束,以调整 Field 的赋值。
- 跨 Field 级别。当变动一个具有其他 Field 之间相互约束的 Field 时,确保保留相关 Field 中的相关信息,并保持对象结构的有效性。
基于 Field 依赖约束的变动
基于对受影响 Field 进行最小修改以避免在变动后破坏有效信息的见解,并利用类层次结构的知识,JDD 实现了以下两种跨 Field 级别的变动器,即嵌套 Field 值重用和顺序固定调整。
嵌套 Field 值重用
在变动特定 Field (即 mutatedField)后,递归检查和调整其相关 Field 。
具体来说,首先根据 IOCD 上的相关支配约束调整 mutatedField 的 Field 。
然后,检测当前约束策略影响的 Field ,并重用变动后和变动前 Field 实例之间共享的实例。
顺序固定调整
如果 JDD 打算变动特定 Field (即 field1),并且存在与多个 Field 相关的约束(即 field2、field3),JDD 分别提取与这三个 Field 相关的约束。
然后调用约束求解器为 field1 找到满足所有相关约束的值,同时尽量减少 field2 和 field3 的调整。
具体来说,约束求解器首先固定 field2 和 field3,然后确定 field1 的适当值。
如果它无法找到满足 field1 的其他约束的解决方案,则逐步调整 field2 和 field3 并继续解决过程。